Visual Question Answering
This is the project page of the UPC team who participated in the VQA challenge in the associated workshop at CVPR 2016.
 |
 |
 |
|---|---|---|
| Main contributor | Advisor | Advisor |
| Issey Masuda Mora | Xavier Giró-i-Nieto | Santiago Pascual de la Puente |
Institution: Universitat Politècnica de Catalunya.

Abstract
Deep learning techniques have been proven to be a great success for some basic perceptual tasks like object detection and recognition. They have also shown good performance on tasks such as image captioning but these models are not that good when a higher reasoning is needed.
Visual Question-Answering tasks require the model to have a much deeper comprehension and understanding of the scene and the realtions between the objects in it than that required for image captioning. The aim of these tasks is to be able to predict an answer given a question related to an image.
Different scenarios have been proposed to tackle this problem, from multiple-choice to open-ended questions. Here we have only addressed the open-ended model.
What are you going to find here
This project gives a baseline code to start developing on Visual Question-Answering tasks, specifically those focused on the VQA challenge. Here you will find an example on how to implement your models with Keras and train, validate and test them on the VQA dataset. Note that we are still building things upon this project so the code is not ready to be imported as a module but we would like to share it with the community to give a starting point for newcomers.
Bachelor thesis
This project has been developed as part of the bachelor thesis of Issey Masuda during Spring 2016 at UPC TelecomBCN ETSETB. The work was graded with the maximum score of 10.0/10.0 (A with honors). The thesis report is available on arXiv and UPCommons.
Citation
Please cite with the following Bibtex code:
@mastersthesis{masuda2016open,
title={Open-ended visual question answering},
author={Masuda Mora, Issey and de la Puente, Santiago and Giro-i-Nieto, Xavier},
type={{B.S.} thesis},
year={2016},
school={Universitat Polit{\`e}cnica de Catalunya}
}
You may also want to refer to our publication with the more human-friendly style:
Issey Masuda, Santiago de la Puente and Xavier Giro-i-Nieto. "Open-ended visual question answering." Bachelor's thesis, Universitat Politècnica de Catalunya, 2016.
Dependencies
This project is build using the Keras library for Deep Learning, which can use as a backend both Theano and TensorFlow.
We have used Theano in order to develop the project and it has not been tested with TensorFlow.
For a further and more complete of all the dependencies used within this project, check out the requirements.txt provided within the project. This file will help you to recreate the exact same Python environment that we worked with.
Project structure
The main files/dir are the following:
- bin: all the scripts that uses the vqa module are here. This is your entry point.
- data: the get_dataset.py script will download the whole dataset for you and place it where it can access it. Alternatively, you can provide the route of the dataset if you have already downloaded it. The vqa module created some directory structure to place preprocessed files
- vqa: this is a python package with the core of the project
- requirements.txt: to be able to reproduce the python environment. You only need to do
pip installin the project's root and it will install all the dependencies needed
The model
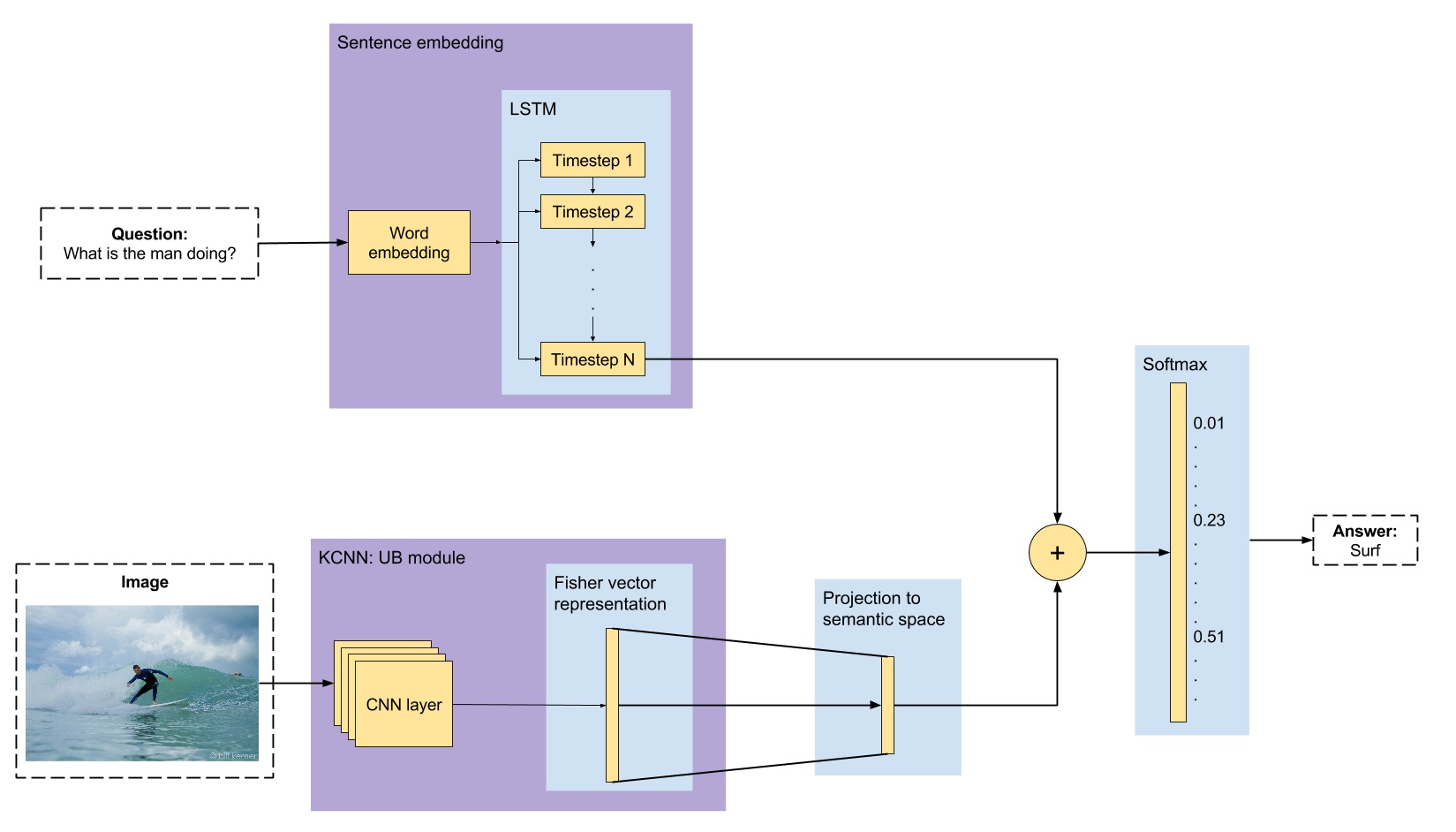
We have participated into the VQA challenge with the following model.
Our model is composed of two branches, one leading with the question and the other one with the image, that are merged to predict the answer. The question branch takes the question as tokens and obtains the word embedding of each token. Then, we feed these word embeddings into a LSTM and we take its last state (once it has seen all the question) as our question representation, which is a sentence embedding. For the image branch, we have first precomputed the visual features of the images with a Kernalized CNNs (KCNNs) [Liu 2015]. We project these features into the same space as the question embedding using a fully-connected layer with ReLU activation function.
Once we have both the visual and text features, we merge them suming both vectors as they belong to the same space. This final representation is given to another fully-connected layer softmax to predict the answer, which will be a one-hot representation of the word (we are predicting a single word as our answer).
Related work
- Ren, Mengye, Ryan Kiros, and Richard Zemel. "Exploring models and data for image question answering." In Advances in Neural Information Processing Systems, pp. 2935-2943. 2015. [code]
- Antol, Stanislaw, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. "VQA: Visual question answering." In Proceedings of the IEEE International Conference on Computer Vision, pp. 2425-2433. 2015. [code]
- Zhu, Yuke, Oliver Groth, Michael Bernstein, and Li Fei-Fei. "Visual7W: Grounded Question Answering in Images." arXiv preprint arXiv:1511.03416 (2015).
- Malinowski, Mateusz, Marcus Rohrbach, and Mario Fritz. "Ask your neurons: A neural-based approach to answering questions about images." In Proceedings of the IEEE International Conference on Computer Vision, pp. 1-9. 2015. [code]
- Xiong, Caiming, Stephen Merity, and Richard Socher. "Dynamic Memory Networks for Visual and Textual Question Answering." arXiv preprint arXiv:1603.01417 (2016). [discussion] [Thew New York Times]
- Serban, Iulian Vlad, Alberto García-Durán, Caglar Gulcehre, Sungjin Ahn, Sarath Chandar, Aaron Courville, and Yoshua Bengio. "Generating Factoid Questions With Recurrent Neural Networks: The 30M Factoid Question-Answer Corpus." arXiv preprint arXiv:1603.06807 (2016). [dataset]
Acknowledgements
We would like to especially thank Albert Gil Moreno and Josep Pujal from our technical support team at the Image Processing Group at the UPC.
 |
 |
|---|---|
| Albert Gil | Josep Pujal |
Contact
If you have any general doubt about our work or code which may be of interest for other researchers, please use the issues section on this github repo. Alternatively, drop us an e-mail at xavier.giro@upc.edu.