



Abstract
We tackle embodied visual navigation in a task-agnostic set-up by putting the focus on the unsupervised discovery of skills (or options) that provide a good coverage of states. Our approach intersects with empowerment: we address the reward-free skill discovery and learning tasks to discover “what” can be done in an environment and “how”. For this reason, we adopt the existing Explore, Discover and Learn (EDL) paradigm, tested only in toy example mazes, and extend it to pixel-based state representations available for embodied AI agents.
If you find this work useful, please consider citing:
Roger Creus, Juan Jose Nieto, and Xavier Giro-i-Nieto. “PixelEDL: Unsupervised Skill Discovery and Learning from Pixels”, 2021.
Find our extended abstract in this PDF.
Talk
Results
The following WandB reports provide more detailed results than those included in the extended abstract.
We experiment with (i) a custom “toy” example Minecraft map; a (ii) realistic Minecraft map; and a (iii) Habitat apartment. We test the performance of contrastive (CURL-ATC) and reconstruction (VQ-VAE) approaches for learning meningful representations of the image observations in a self-supervised manner. Then, we apply a clustering of the embedding space to obtain a finite set of representatives of the representations. In the following reports we show the capabilities of both models for providing valuable features for RL agents. The plots show that the image observations embeddings encode both existing similarities within the state space and spatial relations in the 3D environment. In this way, we provide a framework for empowering agents to discover task-agnostic state-covering skills.
Discovered skills

Reward distribution at the Learning stage
CURL
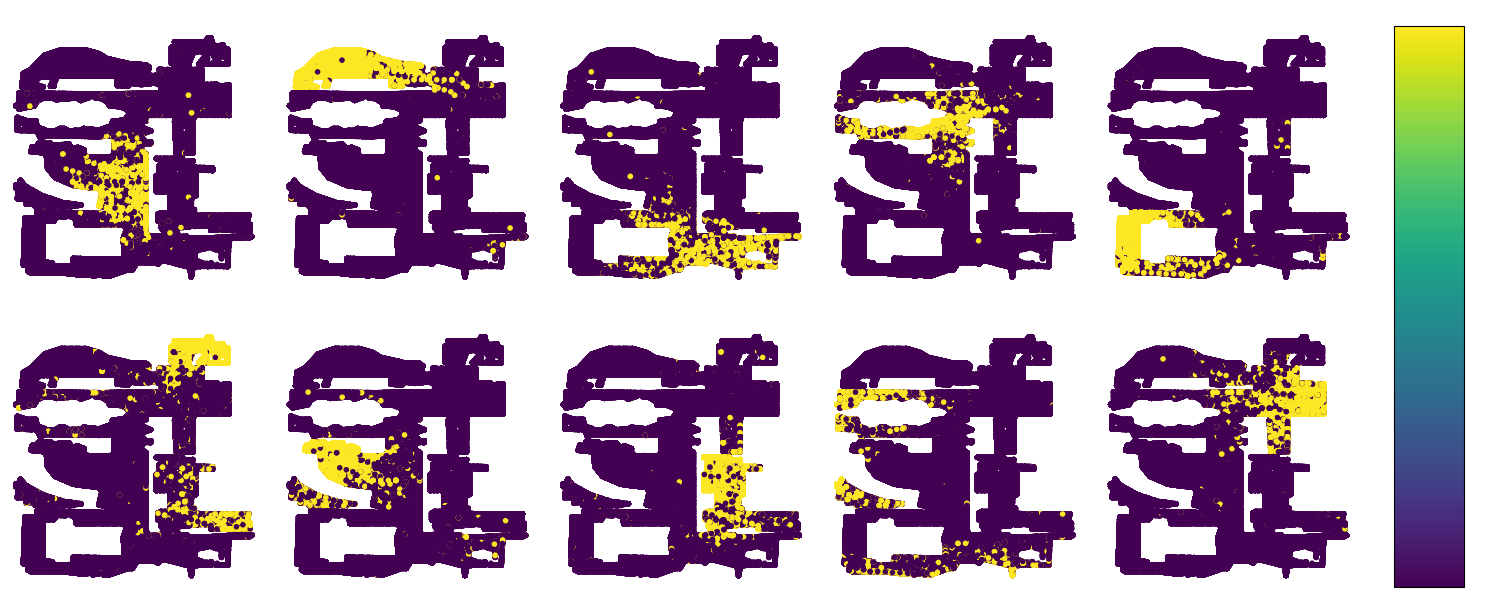

VQ-VAE


Demo
We provide a demo video showing qualitative results of the PixelEDL implementation in the MineRL and Habitat AI environments. The agents skills (policies being learnt) are conditioned with the discovered representative latent variables of the spatial features of the state space. In the video we explicitly show the actual conditioning latent variable for each episode.
code

acknowledgements
We would like to thank Victor Campos for his enriching discussions and mentorship.

We want to thank our wonderful technical support staff:

| We gratefully acknowledge the support of NVIDIA Corporation with the donation of GPUs used in this work. |  |
| This work has been developed in the framework of project TEC2016-75976-R, financed by the Spanish Ministerio de Economía y Competitividad and the European Regional Development Fund (ERDF). |  |