Comparing Fixed and Adaptive Computation Time for Recurrent Neural Networks




![]()
Universitat Politècnica de Catalunya
Barcelona Supercomputing Center
Paper
Deep networks commonly perform better than shallow ones, but allocating the proper amount of computation for each particular input sample remains an open problem. This issue is particularly challenging in sequential tasks, where the required complexity may vary for different tokens in the input sequence. Adaptive Computation Time (ACT) was proposed as a method for dynamically adapting the computation at each step for Recurrent Neural Networks (RNN). ACT introduces two main modifications to the regular RNN formulation: (1) more than one RNN steps may be executed between an input sample is fed to the layer and and this layer generates an output, and (2) this number of steps is dynamically predicted depending on the input token and the hidden state of the network. In our work, we aim at gaining intuition about the contribution of these two factors to the overall performance boost observed when augmenting RNNs with ACT. We design a new baseline, Repeat-RNN, which performs a constant number of RNN state updates larger than one before generating an output. Surprisingly, such uniform distribution of the computational resources matches the performance of ACT in the studied tasks. We hope that this finding motivates new research efforts towards designing RNN architectures that are able to dynamically allocate computational resources.
If you find this work useful, please consider citing:
Daniel Fojo, Victor Campos, Xavier Giro-i-Nieto. “Comparing Fixed and Adaptive Computation Time for Recurrent Neural Networks”, In International Conference on Learning Representations Workshop Track, 2018.
@inproceedings{fojo2018repeat,
title={Comparing Fixed and Adaptive Computation Time for Recurrent Neural Networks},
author={Fojo, Daniel, and Campos, V{\'\i}ctor and Giro-i-Nieto, Xavier},
booktitle={International Conference on Learning Representations Workshop Track},
year={2018}
}
You can find our paper in arXiv, openreview.net, or download the PDF from here.
ACT Model
ACT is an architecture capable of adapt to the complexity of the inputs of a sequence by processing each input more than once, and deciding adaptively how many times each input should be processed.
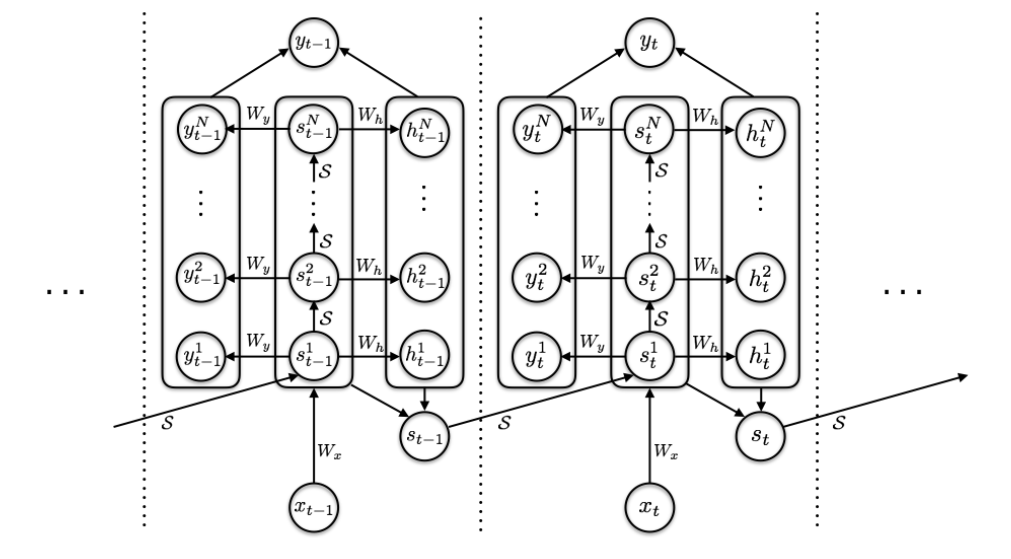
Repeat-RNN
We designed Repeat-RNN a new architecture consisting on repeating the samples of the input sequence of an RNN to compare it with ACT. We decided that this is a fairer comparison than a plain RNN. An example of a sequence and the modified sequence with Repeat-RNN is shown here:

Results
We evaluate the original Adaptive Computation Time model in two of tasks from the original ACT paper: Parity and Addition. We also compared it with our new baseline of repeated inputs, Repeat-RNN. The results were surprising. Repeat-RNN outperforms ACT in learning speed in these two tasks.

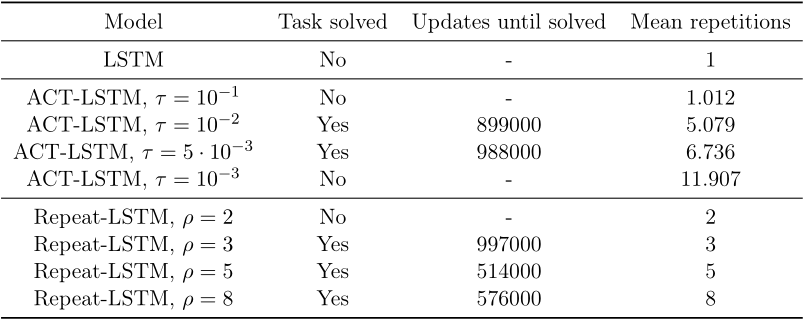
For further discussion of the results, see the full thesis.
Code
This project was developed in Python 3.6.0, and is implimented in both both PyTorch 0.2 and TensorFlow 1.4.
![]()

Acknowledgements
We would like to especially thank the technical support team at the Barcelona Supercomputing Center.
| The Image ProcessingGroup at the UPC is a SGR17 Consolidated Research Group recognized and sponsored by the Catalan Government (Generalitat de Catalunya) through its AGAUR office. |  |
| This work has been supported by the grant SEV2015-0493 of the Severo Ochoa Program awarded by Spanish Government, project TIN2015-65316 by the Spanish Ministry of Science and Innovation contracts 2014-SGR-1051 by Generalitat de Catalunya |  |
| We gratefully acknowledge the support of NVIDIA Corporation for the donation of GPUs. |  |
| This work has been developed in the framework of the project MALEGRA TEC2016-75976-R, funded by the Spanish Ministerio de Economía y Competitividad and the European Regional Development Fund (ERDF). |  |