 |
Paper accepted at Deep Reinforcement Learning Workshop, NIPS 2016 |
|---|
 |
 |
 |
 |
|---|---|---|---|
| Míriam Bellver | Xavier Giro-i-Nieto | Ferran Marques | Jordi Torres |
A joint collaboration between:
 |
 |
|---|---|
| Barcelona Supercomputing Center | UPC Image Processing Group |
Summary
We present a method for performing hierarchical object detection in images guided by a deep reinforcement learning agent. The key idea is to focus on those parts of the image that contain richer information and zoom on them. We train an intelligent agent that, given an image window, is capable of deciding where to focus the attention among five different predefined region candidates (smaller windows). This procedure is iterated providing a hierarchical image analysis. We compare two different candidate proposal strategies to guide the object search: with and without overlap.
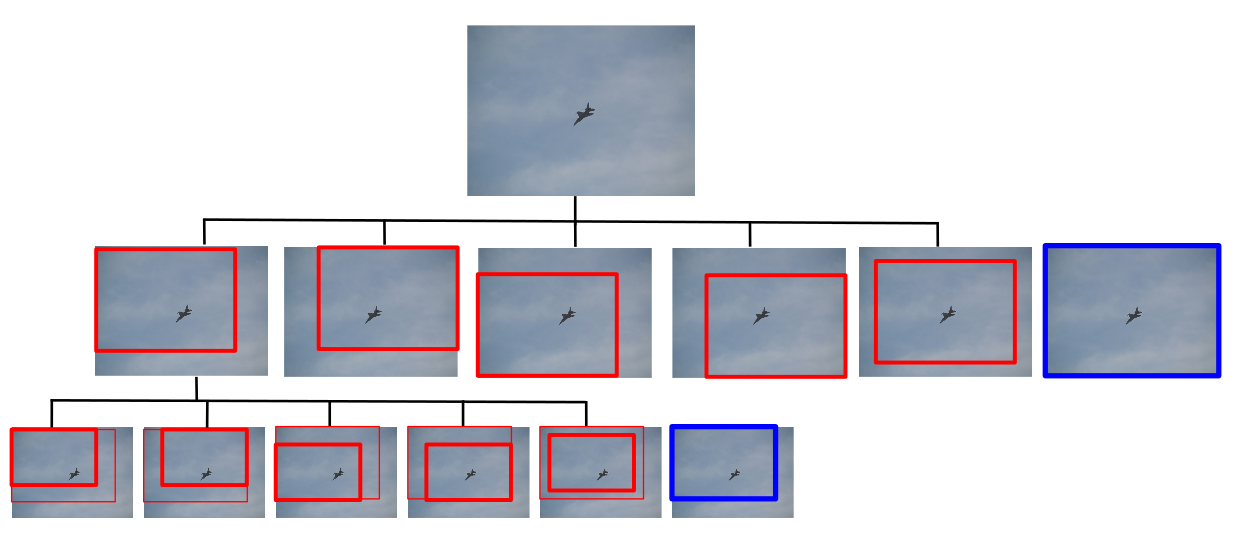
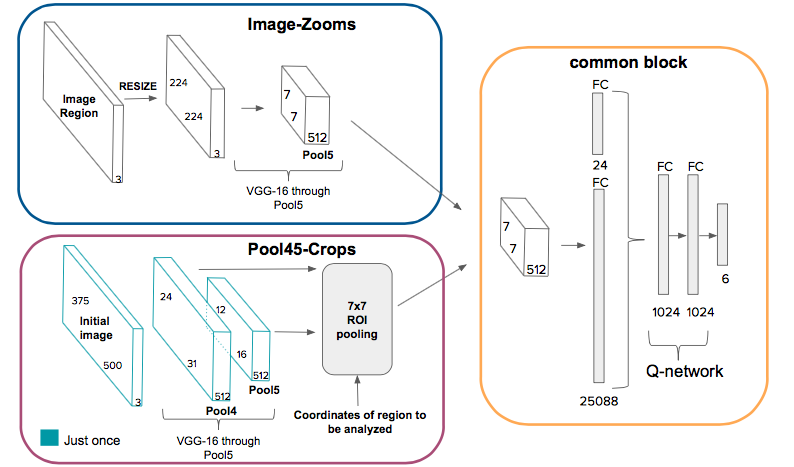
Moreover, our work compares two different strategies to extract features from a convolutional neural network for each region proposal: a first one that computes new feature maps for each region proposal, and a second one that computes the feature maps for the whole image to later generate crops for each region proposal.
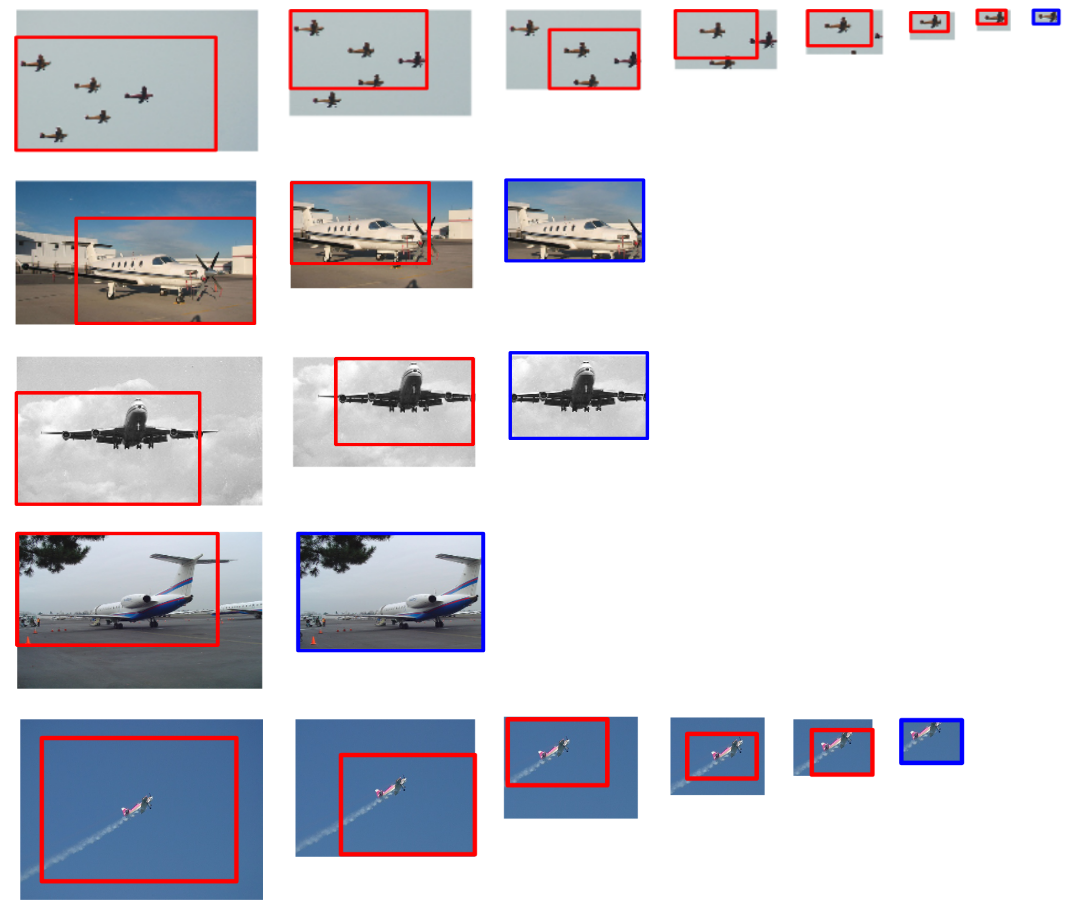
Experiments indicate better results for the overlapping candidate proposal strategy and a loss of performance for the cropped image features due to the loss of spatial resolution. We argue that, while this loss seems unavoidable when working with large amounts of object candidates, the much more reduced amount of region proposals generated by our reinforcement learning agent allows considering to extract features for each location without sharing convolutional computation among regions.
Publication
Our workshop paper is available on arXiv & UPCommons, and related slides here.
Please cite with the following Bibtex code:
@InProceedings{Bellver_2016_NIPSWS,
author = {Bellver, Miriam and Giro-i-Nieto, Xavier and Marques, Ferran and Torres, Jordi},
title = {Hierarchical Object Detection with Deep Reinforcement Learning},
booktitle = {Deep Reinforcement Learning Workshop, NIPS},
month = {December},
year = {2016}
}
You may also want to refer to our publication with the more human-friendly Chicago style:
Miriam Bellver, Xavier Giro-i-Nieto, Ferran Marques, and Jordi Torres. "Hierarchical Object Detection with Deep Reinforcement Learning." In Deep Reinforcement Learning Workshop (NIPS). 2016.
Slides
Talk
Code Instructions
This python code enables to both train and test each of the two models proposed in the paper. The image zooms model extracts features for each region visited, whereas the pool45 crops model extracts features just once and then ROI-pools features for each subregion. In this section we are going to describe how to use the code. The code uses Keras framework library. If you are using a virtual environment, you can use the requirements.txt provided.
First it is important to notice that this code is already an extension of the code used for the paper. During the training stage, we are not only considering one object per image, we are also training for other objects by covering the already found objects with the mean of VGG-16, inspired by what Caicedo et al. did on Active Object Localization with Deep Reinforcement Learning.
Setup
First of all the weights of VGG-16 should be downloaded from the following link VGG-16 weights. If you want to use some pre-trained models for the Deep Q-network, they can be downloaded in the following link Image Zooms model. Notice that these models could lead to different results compared to the ones provided in the paper, due that these models are already trained to find more than one instance of planes in the image. You should also create two folders in the root of the project, called models_image_zooms and models_pool45_crops, and store inside them the corresponding weights.
Usage
Training
We will follow as example how to train the Image Zooms model, that is the one that achieves better results. The instructions are equal for training the Pool45 Crops model. The script is image_zooms_training.py, and first the path to the database should be configured. The default paths are the following:
# path of PASCAL VOC 2012 or other database to use for training
path_voc = "./VOC2012/"
# path of other PASCAL VOC dataset, if you want to train with 2007 and 2012 train datasets
path_voc2 = "./VOC2007/"
# path of where to store the models
path_model = "../models_image_zooms"
# path of where to store visualizations of search sequences
path_testing_folder = '../testing_visualizations'
# path of VGG16 weights
path_vgg = "../vgg16_weights.h5"
But you can change them to point to your own locations.
The training of the models enables checkpointing, so you should indicate which epoch you are going to train when running the script. If you are training it from scratch, then the training command should be:
python image_zooms_training.py -n 0
There are many options that can be changed to test different configurations:
class_object: for which class you want to train the models. We have trained it for planes, and all the experiments of the paper are run on this class, but you can test other categories of pascal, also changing appropiately the training databases.
number_of_steps: For how many steps you want your agent to search for an object in an image.
scale_subregion: The scale of the subregions in the hierarchy, compared to its ancestor. Default value is 3/4, that denoted good results in our experiments, but it can easily be set. Take into consideration that the subregion scale and the number of steps is very correlated, if the subregion scale is high, then you will probably require more steps to find objects.
bool_draw: This is a boolean, that if it is set to 1, it stores visualizations of the sequences for image searches.
At each epoch the models will be saved in the models_image_zooms folder.
Testing
To test the models, you should use the script image_zooms_testing.py. You should also configure the paths to indicate which weights you want to use, in the same manner as in the training stage. In this case, you should only run the command python image_zooms_testing.py. It is recommended that for testing you put bool_draw = 1, so you can observe the visualizations of the object search sequences. There is the option to just search for a single object in each image, to reproduce the same results of our paper, by just setting the boolean only_first_object to 1.
Acknowledgements
We would like to especially thank Albert Gil Moreno and Josep Pujal from our technical support team at the Image Processing Group at the UPC. We also would like to thank Carlos Tripiana from the technical support team at the Barcelona Supercomputing center (BSC).
 |
 |
 |
|---|---|---|
| Albert Gil | Josep Pujal | Carlos Tripiana |
| This work has been supported by the grant SEV2015-0493 of the Severo Ochoa Program awarded by Spanish Government, project TIN2015-65316 by the Spanish Ministry of Science and Innovation contracts 2014-SGR-1051 by Generalitat de Catalunya |  |
| We gratefully acknowledge the support of NVIDIA Corporation with the donation of the GeoForce GTX Titan Z and Titan X used in this work at the UPC, and the BSC/UPC NVIDIA GPU Center of Excellence. |  |
| The Image ProcessingGroup at the UPC is a SGR14 Consolidated Research Group recognized and sponsored by the Catalan Government (Generalitat de Catalunya) through its AGAUR office. |  |
| This work has been developed in the framework of the project BigGraph TEC2013-43935-R, funded by the Spanish Ministerio de Economía y Competitividad and the European Regional Development Fund (ERDF). |  |
Contact
If you have any general doubt about our work or code which may be of interest for other researchers, please use the public issues section on this github repo. Alternatively, drop us an e-mail at miriam.bellver@bsc.es and xavier.giro@upc.edu.