Curriculum Learning for Recurrent Video Object Segmentation
ECCV 2020 Workshops




Abstract
Video object segmentation can be understood as a sequence-to-sequence task that can benefit from the curriculum learning strategies for better and faster training of deep neural networks. This work explores different schedule sampling and frame skipping variations to significantly improve the performance of a recurrent architecture. Our results on the car class of the KITTI-MOTS challenge indicate that, surprisingly, an inverse schedule sampling is a better option than a classic forward one. Also, that a progressive skipping of frames during training is beneficial, but only when training with the ground truth masks instead of the predicted ones.
If you find this work useful, please consider citing:
Maria Gonzalez-i-Calabuig, Carles Ventura, and Xavier Giro-i-Nieto. “Curriculum Learning for Recurrent Video Object Segmentation”, ECCV 2020 Women in Computer Vision Workshop.
Talk
Demo
Qualitative results on the best implementation: inverse step schedule sampling.
Results
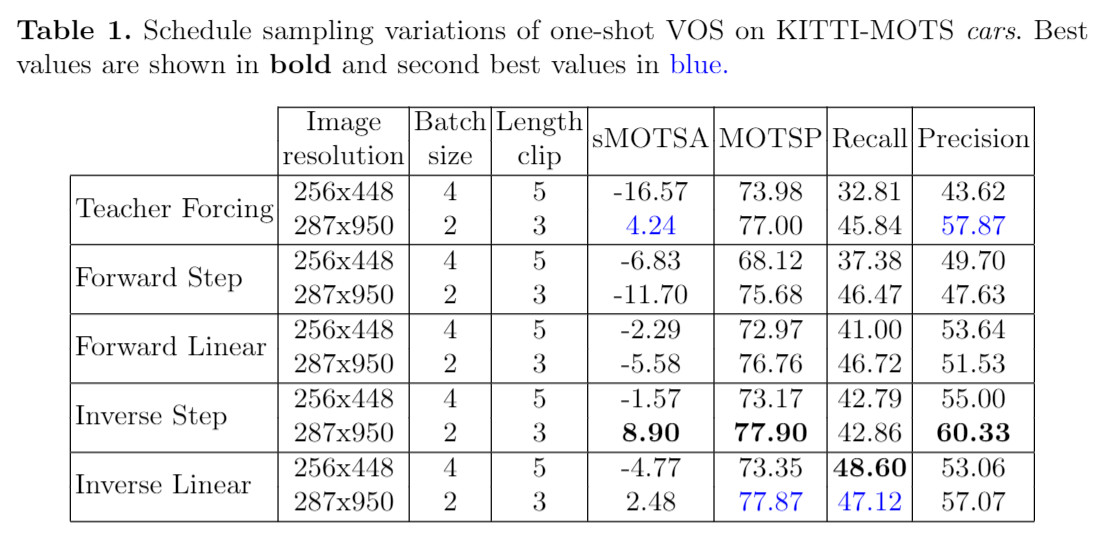
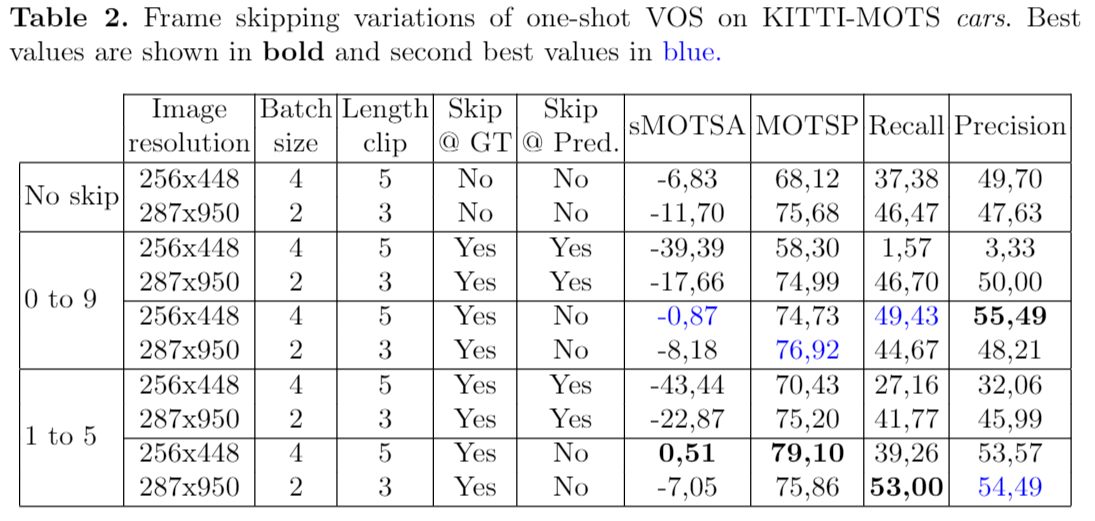
Results for the two curriculum learning strategies: schedule sampling and frame skipping. The addressed task is one-shot or semi-supervided video object segmentation, evaluated on the car class in the validation partition of the KITTI-MOTS benchmark. The official metrics of the MOTS challenge have been adopted.
Model
This work has been developed with RVOS, an recurrent neural network trained end-to-end for video object segmentation which is fast at inference time. The architecture of RVOS is based on an encoder-decoder. For the encoder, a pretrained model of ResNet-101 is used. The decoder is designed as an hierarchical recurrent architecture of Convolutional LSTMs. The cost function that is implemented is the Intersection over Union. RVOS is the fastest model for video object segmentation, able of processing more than 20 frames per second. This fact makes this model an ideal choice for addressing autonomous driving.
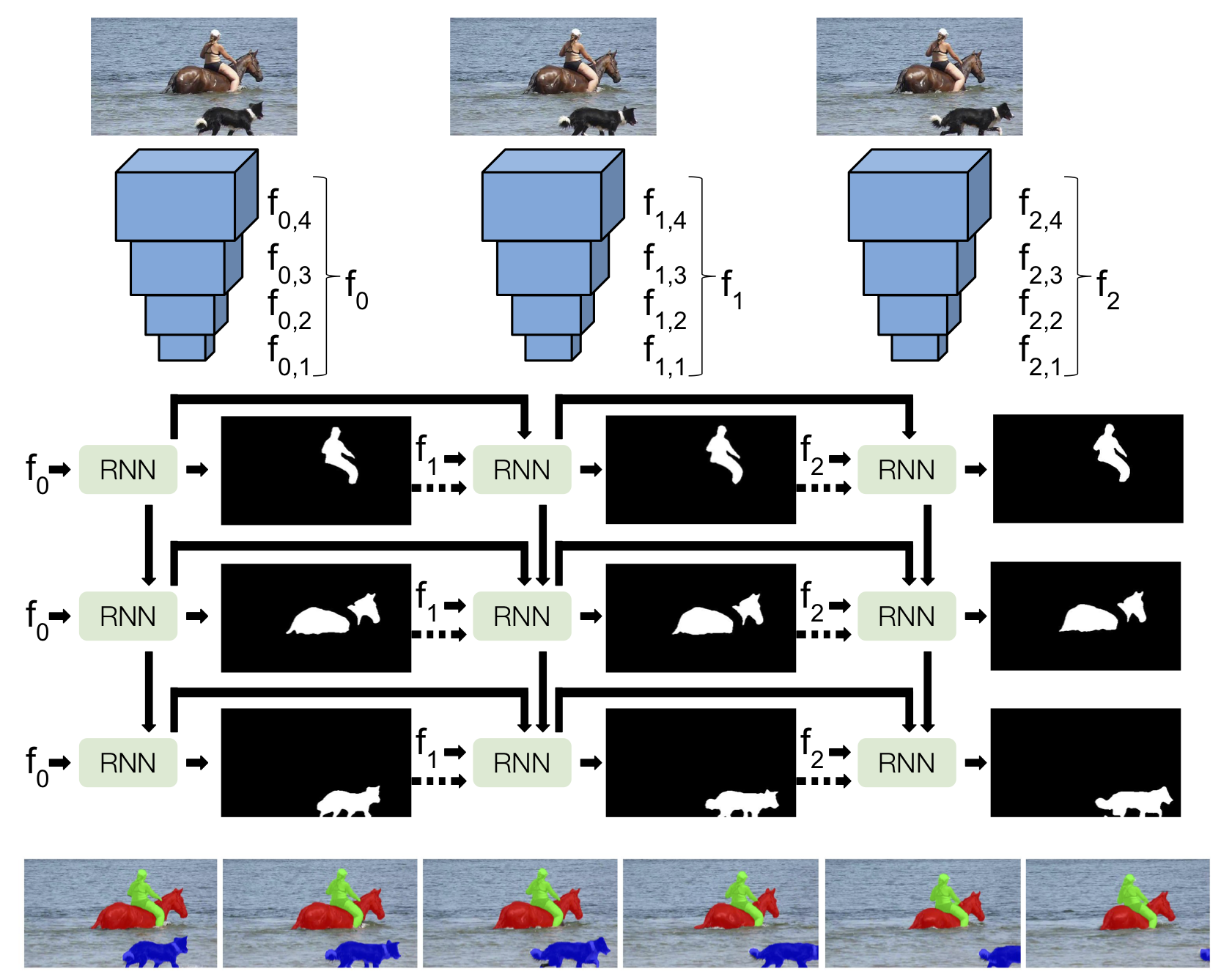
RVOS was developed at the Universitat Oberta de Catalunya, Barcelona Supercomputing Center and Universitat Politècnica de Catalunya and presented in CVPR 2019.
code

acknowledgements
We want to thank our technical support team:

| We gratefully acknowledge the support of NVIDIA Corporation with the donation of the GeForce GTX Titan Z and Titan X used in this work. |  |
| This work has been developed in the framework of projects TEC2013-43935-R and TEC2016-75976-R, financed by the Spanish Ministerio de Economía y Competitividad and the European Regional Development Fund (ERDF). |  |