Wav2Pix:
Speech-conditioned Face Generation using Generative Adversarial Networks
ICASSP 2019












![]()
Universitat Politècnica de Catalunya
Dublin City University
Barcelona Supercomputing Center
Publication
Speech is a rich biometric signal that contains information about the identity, gender and emotional state of the speaker. In this work, we explore its potential to generate face images of a speaker by conditioning a Generative Adversarial Network (GAN) with raw speech input. We propose a deep neural network that is trained from scratch in an end-to-end fashion, generating a face directly from the raw speech waveform without any additional identity information (e.g reference image or one-hot encoding). Our model is trained in a self-supervised fashion by exploiting the audio and visual signals naturally aligned in videos. With the purpose of training from video data, we present a novel dataset collected for this work, with high-quality videos of ten youtubers with notable expressiveness in both the speech and visual signals.
If you find this work useful, please consider citing:
Amanda Duarte, Francisco Roldan, Miquel Tubau, Janna Escur, Santiago Pascual, Amaia Salvador, Eva Mohedano, Kevin McGuinness, Jordi Torres, Xavier Giro-i-Nieto. “Wav2Pix: Speech-conditioned Face Generation using Generative Adversarial Networks”, ICASSP 2019.
@inproceedings{wav2pix2019icassp,
title={Wav2Pix: Speech-conditioned Face Generation
using Generative Adversarial Networks},
author={Amanda Duarte, Francisco Roldan, Miquel Tubau, Janna Escur,
Santiago Pascual, Amaia Salvador, Eva Mohedano, Kevin McGuinness,
Jordi Torres and Xavier Giro-i-Nieto},
booktitle={2019 IEEE International Conference on Acoustics, Speech
and Signal Processing (ICASSP)},
year={2019},
organization={IEEE}
}
Model
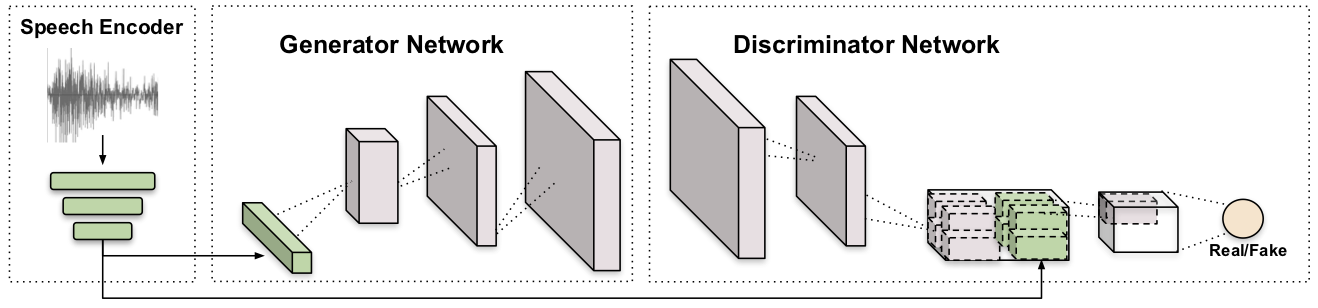
Results
Generated faces compared to a real image from the speech identity, from YouTubers Jaime Altozano (above) and Javier Muñiz (below).

Diversity of identities.

Diversity of expressions.

poster
You can also download the poster as PDF.
code
This project was developed with Python 2.7 and PyTorch 0.4.0. To download and install PyTorch, please follow the official guide. You can also fork or download the project from [here] (https://github.com/miqueltubau/Wav2Pix.git).

acknowledgements
We especially want to thank our technical support team:


| This research has received funding from “la Caixa” Foundation funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 713673. | |
| We gratefully acknowledge the support of NVIDIA Corporation with the donation of the GeForce GTX Titan Z and Titan X used in this work. | |
| The Image Processing Group at the UPC is a SGR17 Consolidated Research Group recognized by the Government of Catalonia (Generalitat de Catalunya) through its AGAUR office. | |
| This research was partially supported by the Spanish Ministry of Economy and Competitivity and the European Regional Development fund under contracts TEC 2015-69266-P and TEC 2016-75976-R, by the Spanish Ministry of Science and Innovation under the contract TIN 2015-65316-P and by the Spanish Government Programa Severo Ochoa under the contract SEV-2015-0493. |
  |
 |
 |